
2018 FIFA 世界杯夺冠预测:结合机器学习与人工智能的高科技分析

数据来源选择
在研究世界杯比赛结果预测时,我挑选了两组数据。这些数据包括了自1930年首届世界杯以来所有参赛队伍的历史比赛成绩。因为FIFA排名是从90年代才开始建立的,所以数据中有很多缺失。所以,我选择了历史比赛记录作为数据支撑,这些详细的历史资料能更准确地展现各队过去的竞技状态。
数据初步处理
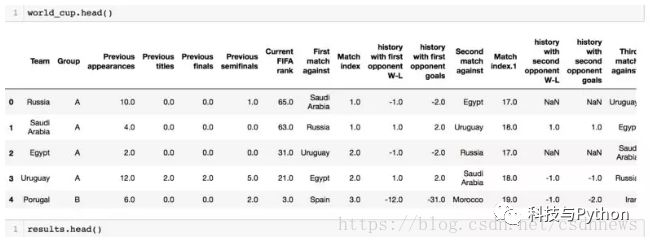
接收到数据集,得先进行初步研究。研究完毕,便构建了一个集成了过往比赛数据的新集合,这对后续研究和预测未来赛事极为有益。在此过程中,还进行了特征选择,筛选出与预测紧密相关的特征,并对数据进行处理,为后续模型建立打下基础。
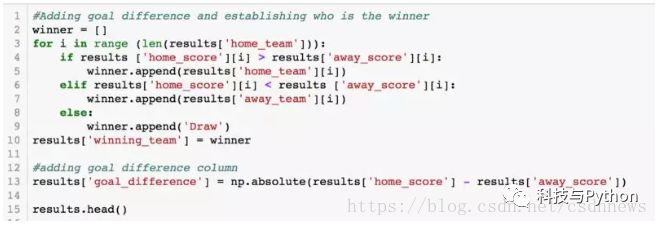
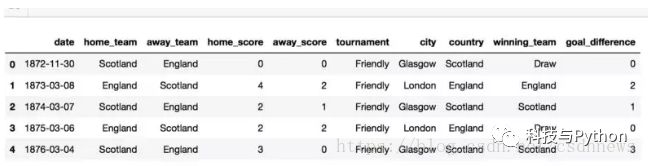
特征深入构建
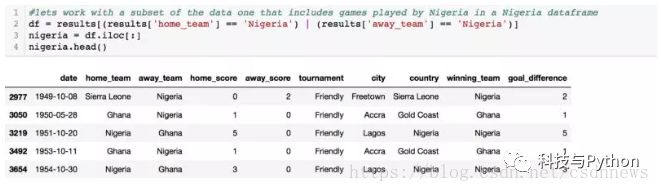
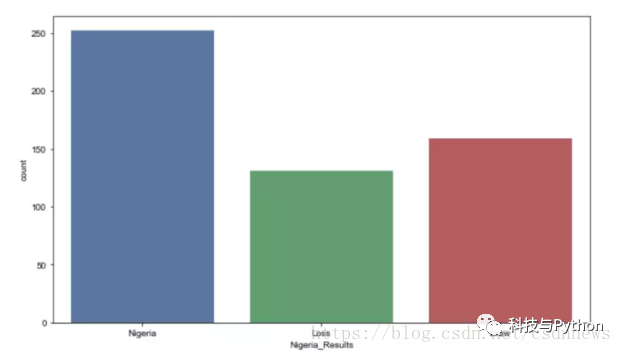
这部分在数据科学项目中尤为耗时。我们会在结果数据集中加入目标差异和结果信息。特别针对尼日利亚的比赛数据进行了专门处理。这样做有助于集中分析一国情况,识别出有效的特征,之后再将这些方法推广至其他参赛国家。此外,我们还能通过图形直观展示尼日利亚历年来的常见比赛结果,使数据更加直观易懂。
关键指标筛选

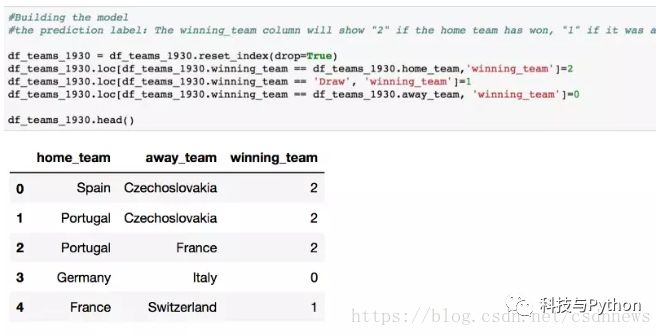
国家胜利的概率是判断比赛胜负的关键因素。借助这一指标,我们可以推断出比赛最有可能的结局。接着,我们从数据集中挑选出自1930年起参加世界杯的队伍,并剔除重复的队伍。同时,为年份设立单独的列,并删除1930年以前以及与比赛结果无关的数据,以此来优化数据架构。

模型学习训练
在实际操作里,我们用两套数据集和比赛的实际成绩,逐场输入算法。算法会学习每条数据对比赛结果的作用,包括正面或负面的影响及其强度。经过充足的数据训练,我们就能得到能预测未来比赛结果的模型。这个模型的优劣,是由输入的数据质量决定的。

模型成效分析
数据经过处理被导入模型,结果显示子训练集准确率是57%,而测试集则是55%。接着,我们引入了2018年4月FIFA的排名及小组赛分组信息。根据队伍排名,新增了预测数据集。模型预测了三场平局,葡萄牙与西班牙将有一队获胜,且西班牙获胜的可能性更大。要提高预测的准确性,一方面可以通过FIFA赛事数据来评估球员实力,从而提升数据集的品质;另一方面,可以尝试将多个模型进行组合。你认为哪种方法更能有效提升预测的准确性?欢迎在评论区留言交流,别忘了点赞和转发这篇文章!
相关文章



