
2022世界杯冠军预测:利用AI模型揭秘足球比赛胜负的靠谱方法
足球比赛往往让人难以预料结果,胜者亦然,这既是大家关注的焦点,也是让人头疼的问题。尽管如此,运用合适的模型对比赛胜者进行预测,仍有一定的可行性。
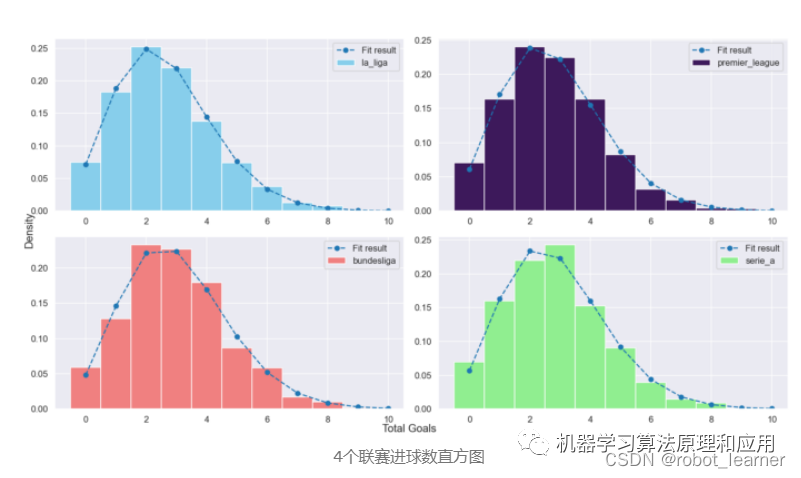
泊松分布的引入
泊松分布是一种描述事件发生次数的离散概率模型。它常用于描述在一定时间或空间范围内的事件发生频率。以足球比赛为例,我们可以将90分钟内的进球数看作是这一时间段内发生的事件,进而计算出相应的概率。以A队和B队的进球数为例,即便假设的2个或3个进球并不完全精确,我们仍可以将其作为实际情况来考虑。这种分布与足球比赛中的进球情况密切相关。众多理论研究也表明,泊松分布适用于此类概率的计算。
采用泊松分布来对足球比赛进行预测,这确实是一种独特的见解。与那些传统预测方法不尽如人意的结果相比,这种方法或许能带来全新的思考视角。
数据的收集
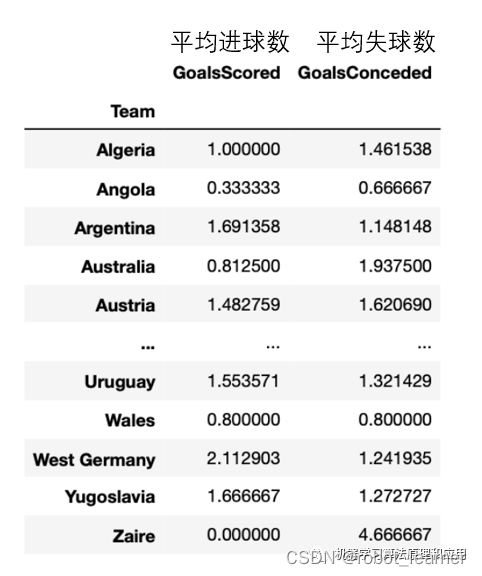
需对各国在赛事中的进球和失球平均值进行统计。涉及的数据包括1930年到2018年间的所有世界杯比赛。这项任务规模庞大,难度不低。
数据必须全面,否则预测将失去根基。准确的数据对预测至关重要,没有它,预测就像空中楼阁一般。若想得到较为准确的预测,我们只得依靠精确有效的数据。
不同赛事的特殊情况
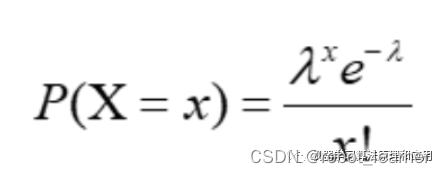
在预测欧洲四大联赛时,主客场因素是必须考虑的。但世界杯比赛在中立场地举行,这一因素无需考虑。不同的比赛在场地设置和规则上有所差异,这些差异都会对预测方法造成影响。
中超赛事中,裁判的判决尺度以及本土特色等因素,都会对比赛结果带来影响。即便是国际上的高水平预测系统,也必须结合实际情况进行相应调整,方能适用于各类赛事。
预测小组赛积分
收集各队的进球数和失球数,之后就能建立一个用来预测小组赛积分的公式。这个过程有专门的代码来辅助,可以精确地算出主队和客队的得分情况。
def predict_points(home, away):
if home in df_team_strength.index and away in df_team_strength.index:
lamb_home = df_team_strength.at[home,'GoalsScored'] * df_team_strength.at[away,'GoalsConceded']
lamb_away = df_team_strength.at[away,'GoalsScored'] * df_team_strength.at[home,'GoalsConceded']
prob_home, prob_away, prob_draw = 0, 0, 0
for x in range(0,11): #number of goals home team
for y in range(0, 11): #number of goals away team
p = poisson.pmf(x, lamb_home) * poisson.pmf(y, lamb_away)
if x == y:
prob_draw += p
elif x > y:
prob_home += p
else:
prob_away += p
points_home = 3 * prob_home + prob_draw
points_away = 3 * prob_away + prob_draw
return (points_home, points_away)
else:
return (0, 0)
代码输出的精确性是有边界的。在实际应用中,误差是难以避免的。然而,通常来说,它还是能给出一个相对合理的积分预测结果。
模拟比赛比分
points_home = 3 * prob_home + prob_draw
points_away = 3 * prob_away + prob_draw
为了增强预测的准确性,我们对从0比0到10比10的各种比分进行了模拟。这样的做法有助于扩大比分预测的范围。
在真正的比赛里,得分情况或许会被这些模拟预测所涵盖。尽管无法保证完全精确,但根据概率学的分析,这些预测已经尽可能地涵盖了大多数可能出现的情形。
>>> predict_points('England', 'United States')
(2.2356147635326007, 0.5922397535606193)
验证与世界杯赢家预测

在各小组赛中,我们运用该函数成功预测了每组的前两名,并据此推定了淘汰赛的参赛选手。经过连续运用这一函数,我们最终预测出了世界杯的冠军。
def get_winner(df_fixture_updated):
for index, row in df_fixture_updated.iterrows():
home, away = row['home'], row['away']
points_home, points_away = predict_points(home, away)
if points_home > points_away:
winner = home
else:
winner = away
df_fixture_updated.loc[index, 'winner'] = winner
return df_fixture_updated
实际上,这些步骤必须多次校验,不能只依赖单次检查。此外,不少数据仍有改进余地,若经过深入优化,将有助于提高预测的准确性。
相关文章



