
基于Python和Spark的大数据处理分析实验指南及案例集锦
import pandas as pd
# 读取数据
file_path = '/home/hadoop/jupyternotebook/lxddashuju/data.csv'
df = pd.read_csv(file_path)
# 查看数据集信息
print(df.info())
# 显示数据的前几行
print(df.head())在当今的体育界,特别是在NBA这样极度依赖数据的比赛里,球员数据的深入剖析越来越受到关注。借助这些数据的分析,我们能够发现众多有价值的资料。
# 1. 去除空值
df.dropna(inplace=True)
print(df.info())# 2. 去除重复值
df.drop_duplicates(inplace=True)
print(df.info())# 3. 处理异常值
# 例如:得分(PTS)、篮板(REB)、助攻(AST)不能为负数
numeric_columns = ['GP', 'Min', 'PTS', 'FGM', 'FGA', 'FG%', '3PM', '3PA', '3P%', 'FTM', 'FTA', 'FT%', 'OREB', 'DREB', 'REB', 'AST', 'TOV', 'STL', 'BLK', 'PF', 'FP', 'DD2', 'TD3']
for col in numeric_columns:
df = df[df[col] >= 0]
print(df.info())数据指标的增添
# 4. 标准化字段名称
df.columns = [col.lower() for col in df.columns]# 查看每个位置的球员数量
pos_counts = df['pos'].value_counts()
print(pos_counts)
SG 96
C 78
SF 77
PG 77
PF 74
G 66
F 66
Name: pos, dtype: int64# 6. 添加新特征
# 添加一个新特征列,例如每分钟得分(PTS per minute)
df['pts_per_minute'] = df['pts'] / df['min']NBA球员数据分析中,增加新的评价标准至关重要。以“得分效率”为例,这一指标是球员每分钟得分情况,加入后能更全面地衡量球员表现。此外,对每位球员的场均篮板、助攻等数据进行计算,例如场均篮板数是总篮板数除以比赛场次,这样可以更精确地评估每位球员的表现。
# 保存清洗后的数据
cleaned_file_path = '/home/hadoop/jupyternotebook/lxddashuju/cleaned_data.csv'
df.to_csv(cleaned_file_path, index=False)
print(f"清洗后的数据已保存到 {cleaned_file_path}")cd /usr/local/hadoop
./sbin/start-dfs.shcd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /usr/local/hadoop球员数据的统计涉及多个维度。比如,计算每支球队的平均得分、篮板和助攻,我们采用特定的公式,例如用sum('pts')/82这样的方法。这样的精确计算能提供更公正的球队平均数据。这有助于我们了解各队在各项指标上的平均表现,并为后续的分析工作打下基础。
cd /usr/local/hadoop
./bin/hdfs dfs -put /home/hadoop/jupyternotebook/dashujufinal/cleaned_data.csv /usr/local/hadoop/clean_data_final.csvcd /usr/local/hadoop
./bin/hdfs dfs -ls /usr/local/hadoop/clean_data_final.csv数据存储的重要性
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, sum, count, when
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number
# 从 HDFS 读取数据
df = spark.read.option("header", True).option("inferSchema", True).csv("hdfs://localhost:9000/usr/local/hadoop/clean_data_final.csv")df.show(3)# 计算每个球员的场均得分、篮板和助攻
df = df.withColumn('avg_points', col('pts') / col('gp')) \
.withColumn('avg_rebounds', col('reb') / col('gp')) \
.withColumn('avg_assists', col('ast') / col('gp')) \
.withColumn('avg_fg%', col('fg%') / 100) \
.withColumn('avg_3p%', col('3p%') / 100) \
.withColumn('win_rate', col('w') / col('gp')) \
.withColumn('lose_rate', col('l') / col('gp'))
# 将数据保存到本地文件
df.toPandas().to_csv('/home/hadoop/jupyternotebook/lxddashuju/result/processed_data.csv')数据计算完毕后,妥善保存至关重要。我们需要将各球队、不同位置和年龄段等数据,如场均得分、篮板和助攻等,录入CSV文件中。这样做便于后续的数据调用、查看和对比。不论是需要分析特定年龄段的数据,还是特定类型的数据,都可以集中存储,确保数据资源得到高效管理。
# 1. 每个球队的场均得分、篮板和助攻
team_stats = df.groupBy('team').agg(
(sum('pts')/82).alias('team_avg_points'),
(sum('reb')/82).alias('team_avg_rebounds'),
(sum('ast')/82).alias('team_avg_assists'),
avg('avg_fg%').alias('team_avg_fg%'),
avg('avg_3p%').alias('team_avg_3p%'),
avg('win_rate').alias('team_win_rate'),
avg('lose_rate').alias('team_lose_rate')
).orderBy(col('team_avg_points').desc()).limit(10)
team_stats.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_stats.csv", header=True)
team_stats.show()在不同的分析层面,数据存储扮演着基石角色。若分析数据未能得到妥善保存,后续分析工作将难以顺利进行。同时,这也使得回顾和对比先前分析成果变得十分困难。
# 2. 计算每个位置的场均得分、篮板和助攻,并包含命中率和三分命中率
pos_stats = df.groupBy('pos').agg(
avg('avg_points').alias('pos_avg_points'),
avg('avg_rebounds').alias('pos_avg_rebounds'),
avg('avg_assists').alias('pos_avg_assists'),
avg('avg_fg%').alias('pos_avg_fg%'),
avg('avg_3p%').alias('pos_avg_3p%')
)
pos_stats.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/pos_stats.csv", header=True)
pos_stats.show()球员个体分析
# 3. 计算每个年龄段的场均得分、篮板和助攻,并包含命中率和三分命中率
age_stats = df.groupBy('age').agg(
avg('avg_points').alias('age_avg_points'),
avg('avg_rebounds').alias('age_avg_rebounds'),
avg('avg_assists').alias('age_avg_assists'),
avg('avg_fg%').alias('age_avg_fg%'),
avg('avg_3p%').alias('age_avg_3p%')
)
age_stats.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/age_stats.csv", header=True)
age_stats.show()球员个人层面,我们通过计算得分与上场时间的比例来衡量效率,即用总得分除以总上场时间得出结果。这样的计算方法可以直观地展示球员的效率。此外,我们还统计了场均助攻数,并新增了相关数据列,这实际上是对球员在场上的个人贡献进行了更为细致的评估。
# 4. 找出每个球队场均得分最高的球员
windowSpec = Window.partitionBy('team').orderBy(col('avg_points').desc())
team_top_scorers = df.withColumn('rank', row_number().over(windowSpec)).filter(col('rank') == 1).select('team', 'pname', 'avg_points')
team_top_scorers.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_top_scorers.csv", header=True)
team_top_scorers.show()# 5. 找出每个位置场均得分最高的球员
windowSpec = Window.partitionBy('pos').orderBy(col('avg_points').desc())
pos_top_scorers = df.withColumn('rank', row_number().over(windowSpec)).filter(col('rank') == 1).select('pos', 'pname', 'avg_points')
pos_top_scorers.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/pos_top_scorers.csv", header=True)
pos_top_scorers.show()球员的数据可以展现他们在队伍中的特殊作用,若某位球员在这些评估标准上表现尤为出色,那么他或许能成为队伍中的核心力量,或是特定战术体系中的关键角色。这样的表现对于球队在制定战术和安排阵容时,无疑提供了宝贵的依据。
# 6. 找出每个年龄段场均得分最高的球员
windowSpec = Window.partitionBy('age').orderBy(col('avg_points').desc())
age_top_scorers = df.withColumn('rank', row_number().over(windowSpec)).filter(col('rank') == 1).select('age', 'pname', 'avg_points')
age_top_scorers.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/age_top_scorers.csv", header=True)
age_top_scorers.show()# 7. 找出场均得分最高的前 10 名球员
top_10_scorers = df.orderBy(col('avg_points').desc()).limit(10).select('pname', 'avg_points', 'team', 'pos', 'age', 'avg_rebounds', 'avg_assists', 'avg_fg%', 'avg_3p%')
top_10_scorers.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/top_10_scorers.csv", header=True)
top_10_scorers.show()线性回归模型应用
# 8. 计算每个球员的场均篮板数
# 计算每个球员的场均篮板数
df = df.withColumn('avg_rebounds', col('reb') / col('gp'))
# 对球员的场均篮板数进行排序
player_avg_rebounds = df.orderBy(col('avg_rebounds').desc()).select('pname', 'avg_rebounds')
player_avg_rebounds.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_avg_rebounds.csv", header=True)
player_avg_rebounds.show()在探讨篮板球与胜利、助攻与失误之间的联系时,我们采用了MLlib的线性回归模型。具体来说,在分析篮板球与胜利的关系时,我们将篮板球数据转换成特征向量;同样的方法也应用于助攻与失误的分析。该模型在预测球员得分能力上表现出色。
# 9. 计算每个球员的场均助攻数
player_avg_assists = df.withColumn('avg_assists', col('ast') / col('gp'))
player_avg_assists = df.orderBy(col('avg_assists').desc()).select('pname', 'avg_assists')
player_avg_assists.show()
player_avg_assists.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_avg_assists.csv", header=True)通过分析,我们可以得出MSE和MAE等评估标准,这些标准显示出预测误差较低。这说明线性回归模型在探究球队比赛中的各种因素关联上相当可靠,有助于辅助球队进行战术调整等决策。
# 10. 计算每个球员的得分与时间的比率(得分/分钟)
player_pts_per_min = df.withColumn('pts_per_minute', col('pts') / col('min'))
player_pts_per_min = df.orderBy(col('pts_per_minute').desc()).select('pname', 'pts_per_minute')
player_pts_per_min.show()
player_pts_per_min.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_pts_per_min.csv", header=True)聚类分析实施
# 11. 分析球员的命中率和三分命中率
player_fg_3p_stats = df.select('pname', 'avg_fg%', 'avg_3p%').orderBy(col('avg_fg%').desc())
player_fg_3p_stats.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_fg_3p_stats.csv", header=True)
player_fg_3p_stats.show()# 12. 分析每个球队的胜率和输率
team_win_lose_rate = df.groupBy('team').agg(
avg('win_rate').alias('team_win_rate'),
avg('lose_rate').alias('team_lose_rate')
).orderBy(col('team_win_rate').desc())
team_win_lose_rate.toPandas().to_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_win_lose_rate.csv", header=True)
team_win_lose_rate.show()进行球员统计数据分类分析是一种有益的探索。我们可以依据球员的平均得分、篮板球和助攻数,将他们划分成不同的类别。接着,利用图表等可视化手段来呈现分析结果。这样的分析方式能清晰揭示球员之间的异同。
观察结果可发现,多数球员的篮板数据集中在特定区间,这一发现对球队在挑选球员及为不同类型球员量身定制训练计划等方面具有重要参考价值。
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression数据可视化呈现
代码执行结果如下图所示:
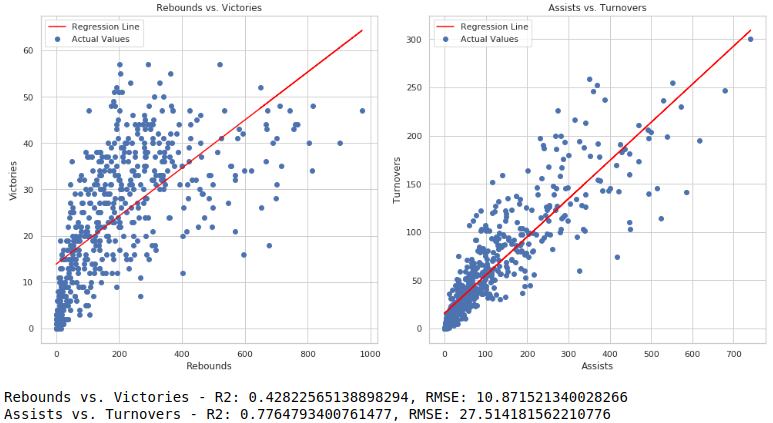
评价指标由模型拟合优度R2和均方根误差RMSE组成,从结果来看,篮板和球队的胜利具有很强的相关性,因为他的RMSE更低,但是线性拟合的效果不是很理想。对于助攻和失误,我们发现他们仍然是具有较强的正相关性,更多的助攻可能会带来更多的失误情况。
## 5.2. 相似性矩阵
计算属性间的相似性矩阵绘制热图,我们可以使用 Spark 将数据转换为 Pandas DataFrame,然后使用 Seaborn 和 Matplotlib 库来绘制热图。
```python
#计算属性间的相似性矩阵
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Convert Spark DataFrame to Pandas DataFrame for correlation computation
df = data.toPandas()
# Compute the correlation matrix
corr = df.corr()
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(corr, dtype=bool))
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(230, 20, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
plt.show()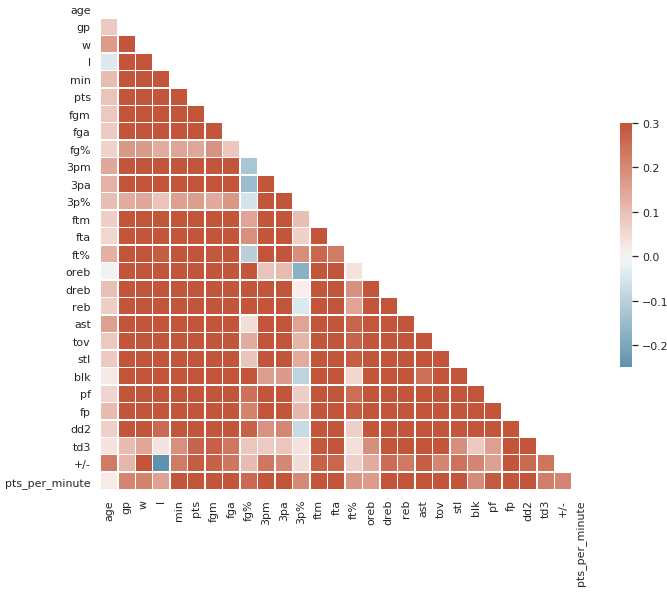
将可视化效果存于网页上颇具实用价值。将数据转换成易于接受的格式,制作成HTML文档,以便展示每个位置的平均得分、篮板以及助攻等具体数据。这样做可以直观且清晰地展现数据状况。
这样的可视化效果对于球队管理者梳理球队情况、媒体进行赛事传播、以及球迷深入理解比赛都具有重要意义。
#NBA球员表现的预测模型
# 创建新特征(例如,每场比赛得分)。
# 删除 PName 列并对分类变量进行编码。
# 将数据分为训练集和测试集。
# 选择一个合适的回归模型(线性回归)。
# 在训练集上训练模型。
# 使用测试集进行预测。
# 计算评估指标(MAE、MSE 和 R-squared)。
# 定义一个函数 predict_points,用于预测特定球员的得分。
# 预测并输出特定球员(例如,Nikola Jokic)在下赛季的得分。
# Create new features
from pyspark.ml.feature import VectorAssembler, StringIndexer
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml import Pipeline
# Create new features
data = data.withColumn("ppg", data["pts"] / data["gp"])
# Index categorical columns
team_indexer = StringIndexer(inputCol="team", outputCol="team_index")
pos_indexer = StringIndexer(inputCol="pos", outputCol="pos_index")
# Assemble features into a feature vector
assembler = VectorAssembler(inputCols=[col for col in data.columns if col not in ['pts', 'pname', 'team', 'pos']], outputCol="features")
# Define the Linear Regression model
lr = LinearRegression(featuresCol="features", labelCol="pts")
# Split the data into a training set and a test set
train_data, test_data = data.randomSplit([0.8, 0.2], seed=42)
# Create a Pipeline
pipeline = Pipeline(stages=[team_indexer, pos_indexer, assembler, lr])
# Train the model
model = pipeline.fit(train_data)
# Make predictions using the test set
predictions = model.transform(test_data)
# Convert predictions to Pandas DataFrame for visualization
predictions_pd = predictions.select("pts", "prediction").toPandas()
# Plotting actual vs predicted points
plt.figure(figsize=(14, 7))
sns.scatterplot(x=predictions_pd["pts"], y=predictions_pd["prediction"])
sns.lineplot(x=predictions_pd["pts"], y=predictions_pd["pts"], color="red", linestyle="--")
plt.xlabel("Actual Points")
plt.ylabel("Predicted Points")
plt.title("Actual vs Predicted Points")
plt.show()
# Evaluate the model
evaluator = RegressionEvaluator(labelCol="pts", predictionCol="prediction", metricName="mae")
mae = evaluator.evaluate(predictions)
evaluator = RegressionEvaluator(labelCol="pts", predictionCol="prediction", metricName="mse")
mse = evaluator.evaluate(predictions)
evaluator = RegressionEvaluator(labelCol="pts", predictionCol="prediction", metricName="r2")
r2 = evaluator.evaluate(predictions)
# Print the evaluation metrics
print(f'Mean Absolute Error (MAE): {mae}')
print(f'Mean Squared Error (MSE): {mse}')
print(f'R-squared: {r2}')
def predict_points(player_name):
# Get the player's data
player_data = data.filter(data['pname'] == player_name)
# Check if the player is in the dataset
if player_data.count() == 0:
print(f"No data available for player: {player_name}")
return None
# Transform the player's data
player_prediction = model.transform(player_data)
# Get the prediction
points_prediction = player_prediction.select("prediction").collect()[0][0]
return points_prediction
# Predict points for a specific player
player_name = "Nikola Jokic" # replace with the name of the player
predicted_points = predict_points(player_name)
if predicted_points is not None:
print(f"Player Name: {player_name}")
print(f"Predicted Points for {player_name} in the next season: {predicted_points:.2f}")
else:
print("Player not found in the dataset.")你懂得如何将这类分析资料应用于NBA比赛的运作吗?欢迎大家在评论区交流,同时期待大家的点赞和转发。

import pandas as pd
# 使用 Pandas 读取 CSV 文件
team_stats = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_stats.csv")
pos_stats = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/pos_stats.csv")
age_stats = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/age_stats.csv")
team_top_scorers = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_top_scorers.csv")
pos_top_scorers = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/pos_top_scorers.csv")
age_top_scorers = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/age_top_scorers.csv")
top_10_scorers = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/top_10_scorers.csv")
player_avg_rebounds = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_avg_rebounds.csv")
player_avg_assists = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_avg_assists.csv")
player_pts_per_min = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_pts_per_min.csv")
player_fg_3p_stats = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/player_fg_3p_stats.csv")
team_win_lose_rate = pd.read_csv("/home/hadoop/jupyternotebook/lxddashuju/result/team_win_lose_rate.csv")
相关文章



